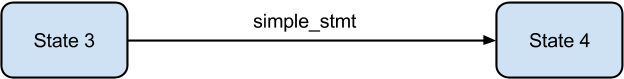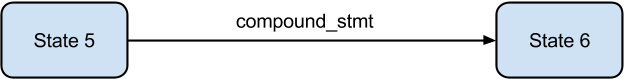This is the first stage in the compilation process of transforming Python code to JavaScript in Skulpt.
As usual, the explanation will be heavily annotated with links to the source code on Github.
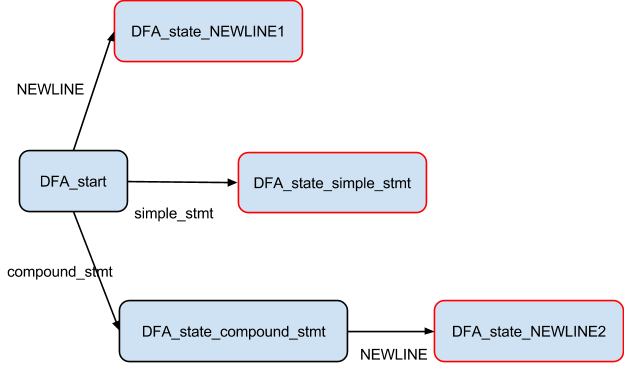
The entrypoint to the CST generation is the call to parse. Each line of the source file is fed to the parser. The parser function is just a wrapper over the tokenization process. It also keeps track of status of parsing and returns the rootnode at the end of a successful parse phase.
Parsing and token generation are interleaved just like in the generation of the parse table. The only difference is that tokens are used for the construction of DFAs in the case of parse table generation, whereas in this case, tokens are used to construct the CST.
One method generates the tokens and the other method consumes them. The generation part is the same as in the generation of the parse table. In fact, the tokenizer code is a port of the Python tokenizer code that was used during generation of parse tables.
The consumer method is just a wrapper around the addToken method which does most of the work of generating the CST.
Consider the simple Python program -
print "hello world"
We shall assume that this program is stored in a file that is fed to the compiler.
The tokens generated for this program are -
As usual, the explanation will be heavily annotated with links to the source code on Github.
The entrypoint to the CST generation is the call to parse. Each line of the source file is fed to the parser. The parser function is just a wrapper over the tokenization process. It also keeps track of status of parsing and returns the rootnode at the end of a successful parse phase.
Parsing and token generation are interleaved just like in the generation of the parse table. The only difference is that tokens are used for the construction of DFAs in the case of parse table generation, whereas in this case, tokens are used to construct the CST.
One method generates the tokens and the other method consumes them. The generation part is the same as in the generation of the parse table. In fact, the tokenizer code is a port of the Python tokenizer code that was used during generation of parse tables.
The consumer method is just a wrapper around the addToken method which does most of the work of generating the CST.
Consider the simple Python program -
print "hello world"
We shall assume that this program is stored in a file that is fed to the compiler.
The tokens generated for this program are -
- (T_NAME, 'print', [1, 0], [1, 5], 'print "hello world"\n')
- (T_STRING, 'hello world', [1, 6], [1, 19], 'print "hello world"\n')
- (T_NEWLINE, '\n', [1, 19], [1, 20], 'print "hello world"\n')
- (T_ENDMARKER, null, [2, 0], [2, 0], null)
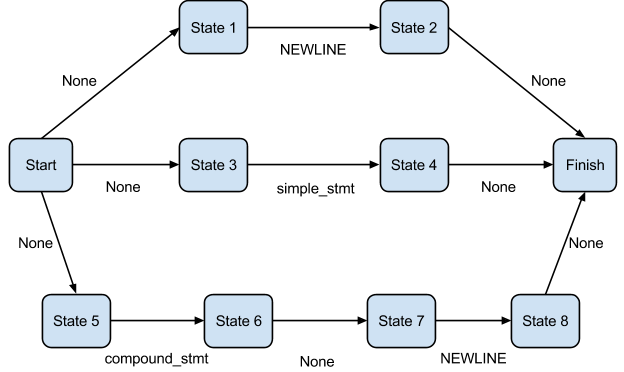
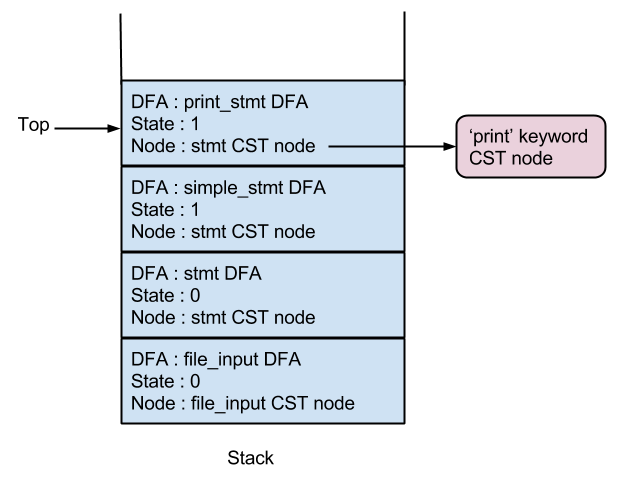
For each of these tokens, the addToken method is called. The addToken method operates on a stack that is initially populated with the stack entry for the start token. The start token in this case is file_input(287) as we provided a file as the input to the compiler.
So, initially the stack looks like this -
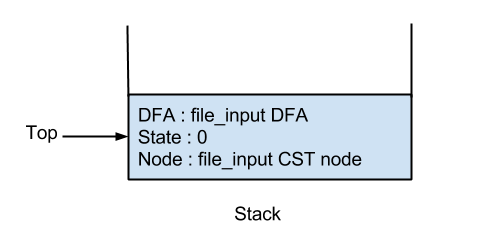

The file_input DFA is here and the file_input CST node has the following form -
{
type : 287,
value : null,
context : null,
children : []
}
[Note : Here context is the same as the line number and column offset]
The addToken method looks at the top of the stack and goes through the states of its DFA till it finds one that has a label matching the current token.
The states of the file_input DFA are
[[[2, 0], [98, 1], [105, 0]], [[0, 1]]]
We only consider state 0 as the stack entry at the top is at state 0.
The first token is the keyword 'print' which is associated with the number 12. We can see that none of the states of the file_input DFA has the number 12. This means that there must be at least one other non_terminal between file_input and the terminal 'print'. Indexing into the labels array with the labels 2, 98, and 105 we get [4, null], [0, null], and [322, null].
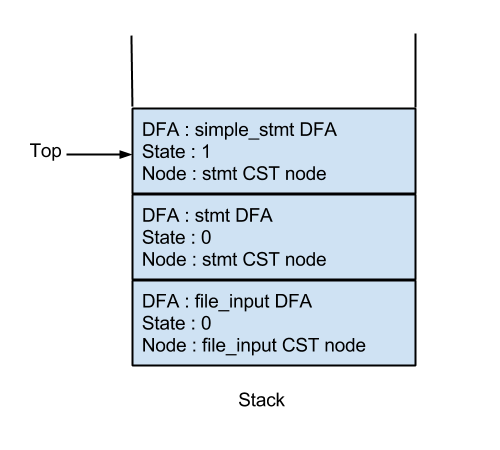
The first non terminal label we encounter is 322 or 'stmt'. As 12 is a valid start symbol for the DFA of 'stmt', we proceed to push a stack entry corresponding to 322 on to the stack. The stack now looks like this -
The stmt CST node is of the form -
{
type : 322,
value : null,
lineno : 1,
col_offset : 0,
children : []
}
This is the general form of the CST nodes.
The same process is repeated for the new stack entry that is on the top. In this case, the state 0 of the 'stmt' DFA is [[1, 1], [3, 1]]. As none of the numbers in this state match 12, we index into the labels array to find [319, null] and [269, null]. As 319 is the first non-terminal encountered, and as 12 is a valid start symbol for its DFA, we push 319 onto the stack and update the state of 'stmt' to 1 (0 in the figure is incorrect). The stack now looks like this -
The next node added is the 'print_stmt'. The 4 labels before it (flow_stmt, assert_stmt, expr_stmt and pass_stmt) are skipped as they do not have 12 in their start symbol dictionary. As 12 is one of the labels in state 0 of the DFA of 'print_stmt', we add the CST node for the 'print' keyword as a child of the 'print_stmt' node. The stack now looks like this -
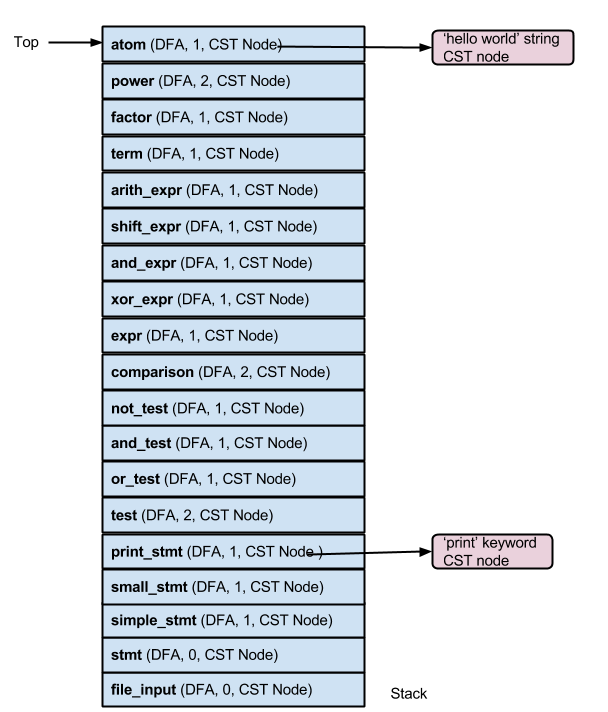
The next set of operations on the stack are straightforward and the resultant stack after the tokens 'print' and 'hello world' have been processed is given below.
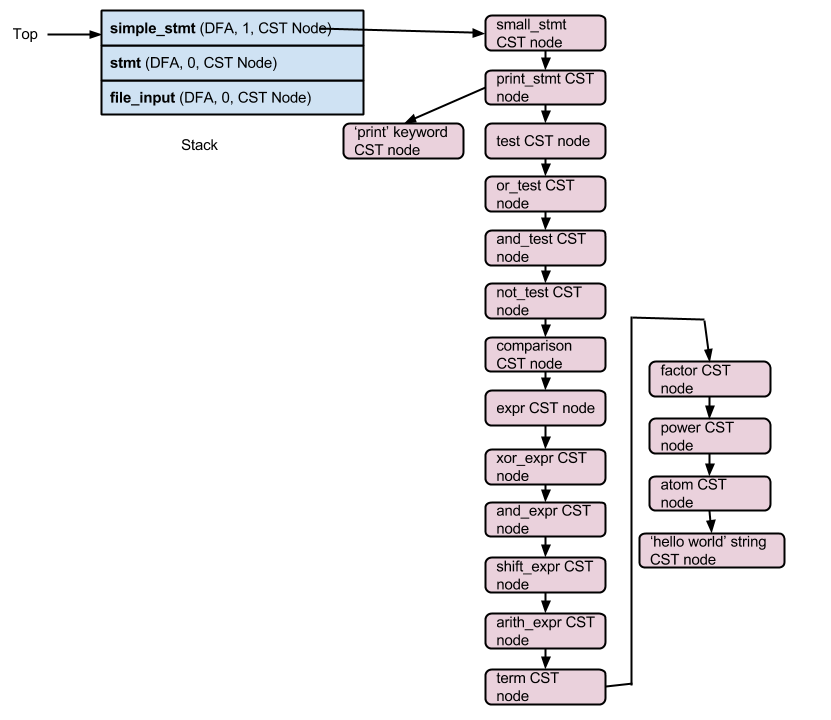
As the DFA for 'atom' is in state 1 which is an accepting state, we can pop 'atom' from the stack. The same goes for all stack entries up to 'small_stmt'. After all the popping, the stack now looks like this -
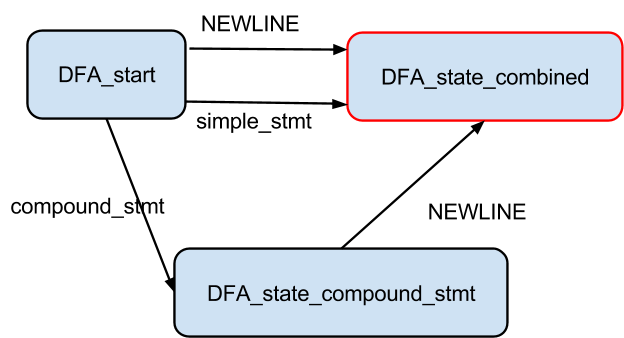
The last two tokens to be processed are the newline and the endmarker tokens. The state 1 of 'simple_stmt' is not an accepting/final state but the newline token takes the 'simple_stmt' dfa from state 1 to 2 which is an accepting state. State 1 of 'stmt' is an accepting state and the endmarker token takes the 'file_input' dfa from state 0 to state 1 which is an accepting state. This empties the stack and results in the final CST.
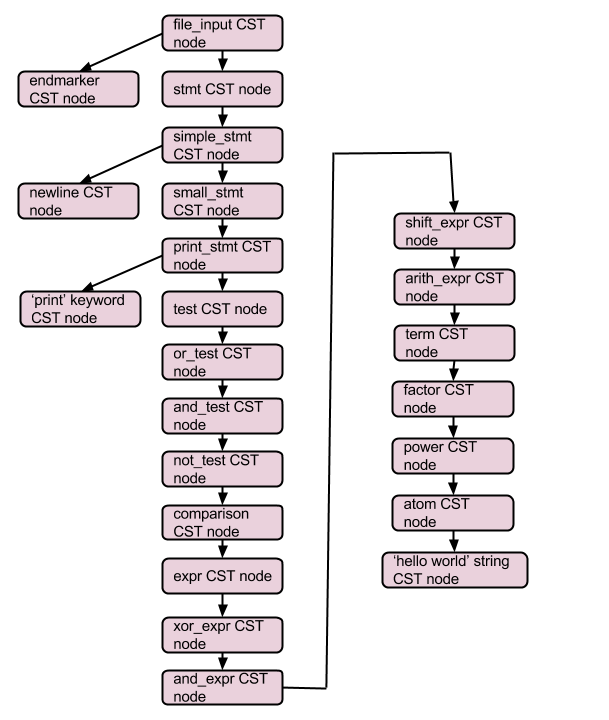 |
| Concrete Syntax Tree |